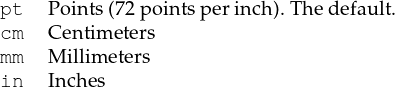
-help --help -version -o -i -idir <directory> -recrypt -decrypt-force -stdout -stdin -stdin-user <password> -stdin-owner <password> -producer <text> -creator <text> -change-id -l -cpdflin <filename> -keep-l -no-preserve-objstm -create-objstm -control <filename> -args <filename> -utf8 -stripped -raw -no-embed-font -gs -gs-malformed -gs-malformed-force -gs-quiet -error-on-malformed
The Coherent PDF tools provide a wide range of facilities for modifying PDF files created by other means. There is a single command-line program cpdf (cpdf.exe under Microsoft Windows). The rest of this manual describes the options that may be given to this program.
The operation -help / --help prints each operation and option together with a short description. The operation -version prints the cpdf version string.
The typical pattern for usage is
cpdf [<operation>] <input file(s)> -o <output file>
cpdf in.pdf -o out.pdf
Files on the command line are distinguished from other input by their containing a period. If an input file does not contain a period, it should be preceded by -i. For example:
cpdf -i in -o out.pdf
cpdf -merge -idir myfiles -o out.pdf
To restrict cpdf to files ending in .pdf (in upper or lower or mixed case) add the option -idir-only-pdfs before -idir:
cpdf -merge -idir-only-pdfs -idir myfiles -o out.pdf
An input range may be specified after each input file. This is treated differently by each operation. For instance
cpdf in.pdf 2-5 -o out.pdf
For example:
cpdf in.pdf 1,2,7-end -o out.pdf
Remove pages three, four, five and six from a document.
cpdf in.pdf 1-16odd -o out.pdf
Extract the odd pages 1,3,...,13,15.
cpdf in.pdf landscape -rotate 90 -o out.pdf
Rotate all landscape pages by ninety degrees.
cpdf in.pdf 1,all -o out.pdf
Duplicate the front page of a document, perhaps as a fax cover sheet.
cpdf in.pdf ˜3-˜1 -o out.pdf
Extract the last three pages of a document, in order.
cpdf in.pdf 2DUP1-10 -o out.pdf
Produce the pages 1,1,2,2,....10,10.
In order to perform many operations, encrypted input PDF files must be decrypted. Some require the owner password, some either the user or owner passwords. Either password is supplied by writing user=<password> or owner=<password> following each input file requiring it (before or after any range). The document will not be re-encrypted upon writing. For example:
cpdf in.pdf user=charles -info
cpdf in.pdf owner=fred reverse -o out.pdf
To re-encrypt the file with its existing encryption upon writing, which is required if only the user password was supplied, but allowed in any case, add the -recrypt option:
cpdf in.pdf user=charles reverse -recrypt -o out.pdf
The password required (owner or user) depends upon the operation being performed. Separate facilities are provided to decrypt and encrypt files (See Section 4).
When appropriate passwords are not available, the option -decrypt-force may be added to the command line to process the file regardless.
Thus far, we have assumed that the input PDF will be read from a file on disk, and the output written similarly. Often it’s useful to be able to read input from stdin (Standard Input) or write output to stdout (Standard Output) instead. The typical use is to join several programs together into a pipe, passing data from one to the next without the use of intermediate files. Use -stdin to read from standard input, and -stdout to write to standard input, either to pipe data between multiple programs, or multiple invocations of the same program. For example, this sequence of commands (all typed on one line)
cpdf in.pdf reverse -stdout | cpdf -stdin 1-5 -stdout | cpdf -stdin reverse -o out.pdf
extracts the last five pages of in.pdf in the correct order, writing them to out.pdf. It does this by reversing the input, taking the first five pages and then reversing the result.
To supply passwords for a file from -stdin, use -stdin-owner <password> and/or -stdin-user <password>.
Using -stdout on the final command in the pipeline to output the PDF to screen is not recommended, since PDF files often contain compressed sections which are not screen-readable.
Several cpdf operations write to standard output by default (for example, listing fonts). A useful feature of the command line (not specific to cpdf) is the ability to redirect this output to a file. This is achieved with the > operator:
cpdf -info in.pdf > file.txt
Use the -info operation (See Section 11.1), redirecting the output to file.txt.
The keyword AND can be used to string together several commands in one. The advantage compared with using pipes is that the file need not be repeatedly parsed and written out, saving time.
To use AND, simply leave off the output specifier (e.g -o) of one command, and the input specifier (e.g filename) of the next. For instance:
cpdf -merge in.pdf in2.pdf AND -add-text "Label" AND -merge in3.pdf -o out.pdf
Merge in.pdf and in2.pdf together, add text to both pages, append in3.pdf and write to out.pdf.
To specify the range for each section, use -range:
cpdf -merge in.pdf in2.pdf AND -range 2-4 -add-text "Label" AND -merge in3.pdf -o out.pdf
When measurements are given to cpdf, they are in points (1 point = 1/72 inch). They may optionally be followed by some letters to change the measurement. The following are supported:
For example, one may write 14mm or 21.6in. In addition, the following letters stand,
in some operations (-scale-page, -scale-to-fit, -scale-contents, -shift,
-mediabox,
-crop) for various page dimensions:

For example, we may write PMINXPMINY to stand for the coordinate of the lower left corner of the page.
Simple arithmetic may be performed using the words add, sub, mul and div to stand for addition, subtraction, multiplication and division. For example, one may write 14in sub 30pt or PMINX mul 2
The -producer and -creator options may be added to any cpdf command line to set the producer and/or creator of the PDF file. If the file was converted from another format, the creator is the program producing the original, the producer the program converting it to PDF.
cpdf -merge in.pdf in2.pdf -producer MyMerger -o out.pdf
Merge in.pdf and in2.pdf, setting the producer to MyMerger and writing the output to out.pdf.
When an operation which uses a part of the PDF standard which was introduced in a later version than that of the input file, the PDF version in the output file is set to the later version (most PDF viewers will try to load any PDF file, even if it is marked with a later version number). However, this automatic version changing may be suppressed with the -keep-version option. If you wish to manually alter the PDF version of a file, use the -set-version operation described in Section 18.5.
PDF files contain an ID (consisting of two parts), used by some workflow systems to uniquely identify a file. To change the ID, behavior, use the -change-id operation. This will create a new ID for the output file.
cpdf -change-id in.pdf -o out.pdf
Write in.pdf to out.pdf, changing the ID.
Linearized PDF is a version of the PDF format in which the data is held in a special manner to allow content to be fetched only when needed. This means viewing a multipage PDF over a slow connection is more responsive. By default, cpdf does not linearize output files. To make it do so, add the -l option to the command line, in addition to any other command being used. For example:
cpdf -l in.pdf -o out.pdf
Linearize the file in.pdf, writing to out.pdf.
This requires the existence of the external program cpdflin which is provided with commercial versions of cpdf. This must be installed as described in the installation documentation provided with your copy of cpdf. If you are unable to install cpdflin, you must use -cpdflin to let cpdf know where to find it:
cpdf.exe -cpdflin "C:' ' cpdflin.exe" -l in.pdf -o out.pdf
Linearize the file in.pdf, writing to out.pdf.
In extremis, you may place cpdflin and its resources in the current working directory, though this is not recommended. For further help, refer to the installation instructions for your copy of cpdf.
To keep the existing linearization status of a file (produce linearized output if the input is linearized and the reverse), use -keep-l instead of -l.
PDF 1.5 introduced a new mechanism for storing objects to save space: object streams. by default, cpdf will preserve object streams in input files, creating no more. To prevent the retention of existing object streams, use -no-preserve-objstm:
cpdf -no-preserve-objstm in.pdf -o out.pdf
Write the file in.pdf to out.pdf, removing any object streams.
To create new object streams if none exist, or augment the existing ones, use -create-objstm:
cpdf -create-objstm in.pdf -o out.pdf
Write the file in.pdf to out.pdf, preserving any existing object streams, and creating any new ones for new objects which have been added.
To create wholly new object streams, use both options together:
cpdf -create-objstm -no-preserve-objstm in.pdf -o out.pdf
Write the file in.pdf to out.pdf with wholly new object streams.
Files written with object streams will be set to PDF 1.5 or higher, unless -keep-version is used (see above).
There are many malformed PDF files in existence, including many produced by otherwise-reputable applications. cpdf attempts to correct these problems silently.
Grossly malformed files will be reconstructed. The reconstruction progress is shown on stderr (Standard Error):
$cpdf in.pdf -o out.pdf
couldnt lex object number
Attempting to reconstruct the malformed pdf in.pdf...
Read 5530 objects
Malformed PDF reconstruction succeeded!
If cpdf cannot reconstruct a malformed file, it is able to use the gs program to try to reconstruct the PDF file, if you have it installed. For example, if gs is installed and in your path, we might try:
cpdf -gs gs -gs-malformed in.pdf -o out.pdf
To suppress the output of gs use the -gs-quiet option.
If the malformity lies inside an individual page of the PDF, rather than in its gross structure, cpdf may appear to succeed in reconstruction, only to fail when processing a page (e.g when adding text). To force the use of gs to pre-process such files so cpdf cannot fail on them, use -gs-malformed-force:
cpdf in.pdf -gs gs -gs-malformed-force -o out.pdf [-gs-quiet]
The command line for -gs-malformed-force must be of precisely this form. Sometimes, on the other hand, we might wish cpdf to fail immediately on any malformed file, rather than try its own reconstruction process. The option -error-on-malformed achieves this.
Sometimes (old, pre-ISO standardisation) files can be technically well-formed but use inefficient PDF constructs. If you are sure the input files you are using are well formed, the -fast option may be added to the command line (or, if using AND, to each section of the command line). This will use certain shortcuts which speed up processing, but would fail on badly-produced files. The -fast option may be used with:
Chapter 3
-rotate-contents -upright -vflip -hflip
-shift -scale-page -scale-to-fit -scale-contents
-show-boxes -hard-box -trim-marks
Chapter 8
-add-text -add-rectangle
-stamp-on -stamp-under -combine-pages
Chapter 9
-impose -impose-xy -twoup -twoup-stack
If problems occur, refrain from using -fast.
When cpdf encounters an error, it exits with code 2. An error message is displayed on stderr (Standard Error). In normal usage, this means it’s displayed on the screen. When a bad or inappropriate password is given, the exit code is 1.
cpdf -control <filename>
cpdf -args <filename>
Some operating systems have a limit on the length of a command line. To circumvent this, or simply for reasons of flexibility, a control file may be specified from which arguments are drawn. This file does not support the full syntax of the command line. Commands are separated by whitespace, quotation marks may be used if an argument contains a space, and the sequence ' " may be used to introduce a genuine quotation mark in such an argument.
Several -control arguments may be specified, and may be mixed in with conventional command-line arguments. The commands in each control file are considered in the order in which they are given, after all conventional arguments have been processed. It is recommended to use -args in all new applications. However, -control will be supported for legacy applications.
To avoid interference between -control and AND, a new mechanism has been added. Using -args in place of -control will perform direct textual substitution of the file into the command line, prior to any other processing.
Command lines are handled differently on each operating system. Some characters are reserved with special meanings, even when they occur inside quoted string arguments. To avoid this problem, cpdf performs processing on string arguments as they are read.
A backslash is used to indicate that a character which would otherwise be treated specially by the command line interpreter is to be treated literally. For example, Unix-like systems attribute a special meaning to the exclamation mark, so the command line
cpdf -add-text "Hello!" in.pdf -o out.pdf
cpdf -add-text "Hello' !" in.pdf -o out.pdf
Some cpdf commands write text to standard output, or read text from the command line or configuration files. These are:
-info
-list-bookmarks
-set-author et al.
-list-annotations
-dump-attachments
There are three options to control how the text is interpreted:
-utf8
-stripped
-raw
Add -utf8 to use Unicode UTF8, -stripped to convert to 7 bit ASCII by dropping any high characters, or -raw to perform no processing. The default unless specified in the documentation for an individual operation is -stripped.
Use the -no-embed-font to avoid embedding the Standard 14 Font metrics when adding text with -add-text.