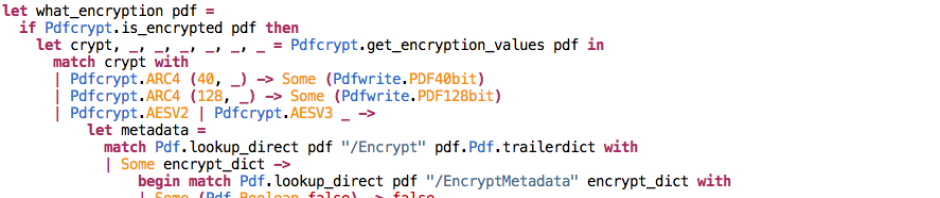
(If you’re reading this via the OCaml planet, click the post title to see it with proper formatting – I shall fix this problem for the next post, I hope.)
When calling our command line PDF Tools to, for instance, merge files, one can use page specifiers with a simple grammar. For instance:
cpdf file.pdf 1,2,6-end -o out.pdf
cpdf in.pdf 1,all -o fax.pdf
(The second example is useful to duplicate the first page of a document as a fax cover sheet)
If the grammar is simple, OCaml’s Genlex plus a small recursive parser is sufficient.
Here’s an informal description of the mini language:
• A dash (-) defines ranges, e.g. 1-5 or 6-3.
• A comma (,) allows one to specify several ranges, e.g. 1-2,4-5.
• The word “end” represents the last page number.
• The words “odd” and “even” represent the odd and even pages.
• The word “reverse” is the same as end-1.
• The word “all” is the same as 1-end.
• A range must contain no spaces.
Our input is the string in this language, our output an ordered list of page numbers. (I’m using some functions from the Utility module available with CamlPDF)
First build a lexer:
let lexer =
Genlex.make_lexer [“-“; “,”; “all”; “reverse”; “even”; “odd”; “end”]
and define a utility function which lexes a string to a list of Genlex lexemes (no need to be lazy here):
let lexwith s =
list_of_stream (lexer (Stream.of_string s))
Now, this language is quite simple to deal with. We’ll pattern-match for all the simple cases – anything which doesn’t contain a comma is finite. If nothing matches, we assume the string contains one or more commas, and attempt to split it up.
Here is the main function, which is given the end page of the PDF file to which the range applies (the start page is always 1), and a list of tokens to match against:
let rec mk_numbers endpage = function
| [Genlex.Int n] -> [n]
| [Genlex.Int n; Genlex.Kwd “-“; Genlex.Int n’] ->
if n > n’ then rev (ilist n’ n) else ilist n n’
| [Genlex.Kwd “end”; Genlex.Kwd “-“; Genlex.Int n] ->
if n <= endpage
then rev (ilist n endpage)
else failwith “n > endpage”
| [Genlex.Int n; Genlex.Kwd “-“; Genlex.Kwd “end”] ->
if n <= endpage
then ilist n endpage
else failwith “n > endpage2”
| [Genlex.Kwd “end”; Genlex.Kwd “-“; Genlex.Kwd “end”] ->
[endpage]
| [Genlex.Kwd “even”] ->
drop_odds (ilist 1 endpage)
| [Genlex.Kwd “odd”] ->
really_drop_evens (ilist 1 endpage)
| [Genlex.Kwd “all”] ->
ilist 1 endpage
| [Genlex.Kwd “reverse”] ->
rev (ilist 1 endpage)
| toks ->
let ranges = splitat_commas toks in
(* Check we’ve made progress *)
if ranges = [toks] then error “Bad page range” else
flatten (map (mk_numbers endpage) ranges)
(ilist x y produces the list [x, x + 1, … y – 1, y], drop_odds [1;2;3;4;5;6;7] is [2;4;6], really_drop_evens [1;2;3;4;5;6] is [1;3;5])
The auxilliary function to split a token list at commas into a list of token lists:
let rec splitat_commas toks =
match cleavewhile (neq (Genlex.Kwd “,”)) toks with
| [], _ -> []
| some, [] -> [some]
| _::_ as before, _::rest -> before::splitat_commas rest
(cleavewhile returns, in order, the elements at the beginning of a list until a predicate is false, paired with the rest of the elements, in order. neq is ( <> ))
And here’s the wrapper function, which unifies the error handling and tests for page numbers not within range.
let parse_pagespec pdf spec =
let endpage = endpage_of_pdf pdf in
let numbers =
try mk_numbers endpage (lexwith spec) with
_ -> error (“Bad page specification ” ^ spec)
in
iter
(fun n -> if n <> endpage then
error (“Page ” ^ string_of_int n ^ ” does not exist.”))
numbers;
numbers
This is often easier to write and debug than using a separate tool intended for highly complex grammars.